There are two basic categories of failures, which you’ll want to handle differently:
- Transient, self-healing failures such as intermittent network connectivity issues.
- Enduring failures that require intervention.
For enduring failures, you can implement monitoring and logging functionality that notifies you promptly when issues arise and that facilitates root-cause analysis.
Machine failures is fairly common in the cloud world. How do we get machine resiliency?



Machine failures is fairly common in the cloud world. How do we get machine resiliency?



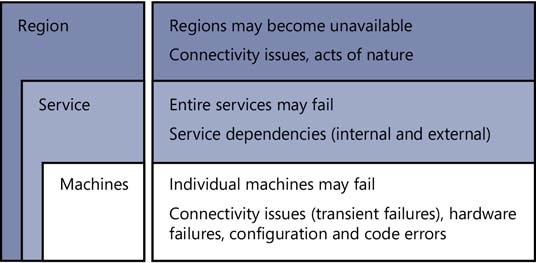
FAILURE SCOPE
You also have to think about failure scope—whether a single machine is affected, a whole service such as SQL Database or Storage, or an entire region.
Machine failures
In Azure, a failed server is automatically replaced by a new one, and a well-designed cloud app recovers from this kind of failure automatically and quickly. Earlier, we stressed the scalability benefits of a stateless web tier, and ease of recovery from a failed server is another benefit of statelessness. Ease of recovery is also one of the benefits of platform-as-a-service (PaaS) features such as SQL Database and Web Apps. Hardware failures are rare, but when they occur, these services handle them automatically; you don’t even have to write code to handle machine failures when you’re using one of these services.
Service failures
Cloud apps typically use multiple services. For example, the Fix It app uses the SQL Database service and the Storage service, and it’s deployed to the Web Apps service. What will your app do if one of the services you depend on fails? For some service failures a friendly “Sorry, try again later” message might be the best you can do. But in many scenarios you can do better. For example, when your back-end data store is down, you can accept user input, display “Your request has been received,” and store the input someplace else temporarily. Then, when the service you need is operational again, you can retrieve the input and process it.
Chapter 13, “Queue-centric work pattern,” shows one way to handle this scenario. The Fix It app stores tasks in SQL Database, but it doesn’t have to quit working when SQL Database is down. In that chapter you'll see how to store user input for a task in a queue and use a worker process to read the queue and update the task. If SQL Database is down, the ability to create Fix It tasks is unaffected; the worker process can wait and process new tasks when SQL Database is available.
Region failures
Entire regions may fail. A natural disaster might destroy a data center—it might be flattened by a meteor, the trunk line into the datacenter could be cut by a farmer burying a cow with a backhoe, etc. If your app is hosted in the stricken data center, what do you do? It’s possible to set up your app in Azure to run in multiple regions simultaneously so that if a disaster occurs in one, your app continues running in another region. Such failures are extremely rare occurrences, and most apps don’t jump through the hoops necessary to ensure uninterrupted service through failures of this sort. See the Resources section at the end of the chapter for information about how to keep your app available even through a region failure.
A goal of Azure is to make handling these kinds of failures a lot easier, and you’ll see some examples of how Azure does that in the following chapters.