 |
Sunday, May 24, 2015
CHOOSING A DATA STORAGE OPTION
CHOOSING A DATA STORAGE OPTION
No one approach is right for all scenarios. If anyone says that a particular technology is the answer, the first thing to ask is "What is the question?" because different solutions are optimized for different things. The relational model has definite advantages; that’s why it’s been around for so long. But there are also downsides to SQL that can be addressed with a NoSQL solution.
Often, what we see work best is a composite approach in which SQL and NoSQL are used in a single solution. Even when people say they’re embracing NoSQL, a closer looks reveals that they’re using several different NoSQL frameworks—they’re using CouchDB, Redis, and Riak for different things. Even Facebook, which uses NoSQL solutions extensively, uses different NoSQL frameworks for different parts of the service. The flexibility to mix and match data storage approaches is one of the qualities that’s nice about the cloud; it’s easy to use multiple data solutions and integrate them in a single app.
Here are some questions to think about when you’re choosing an approach:
| Data semantic | What is the core data storage and data access semantic (are you storing relational or unstructured data)? Unstructured data such as media files fits best in Blob storage; a collection of related data such as products, inventories, suppliers, customer orders, etc., fits best in a relational database. |
| Query support | How easy is it to query the data? What types of questions can be efficiently asked? Key/value data stores are very good at getting a single row when given a key value, but they are not so good for complex queries. For a user-profile data store in which you are always getting the data for one particular user, a key/value data store could work well. For a product catalog from which you want to get different groupings based on various product attributes, a relational database might work better. NoSQL databases can store large volumes of data efficiently, but you have to structure the database around how the app queries the data, and this makes ad hoc queries harder to do. With a relational database, you can build almost any kind of query. |
| Functional projection | Can questions, aggregations, and so on be executed on the server? If you run SELECT COUNT(*) from a table in SQL, the DBMS will very efficiently do all the work on the server and return the number you’re looking for. If you want the same calculation from a NoSQL data store that doesn't support aggregation, this operation is an inefficient “unbounded query” and will probably time out. Even if the query succeeds, you have to retrieve all the data from the server and bring it to the client and count the rows on the client. What languages or types of expressions can be used? With a relational database, you can use SQL. With some NoSQL databases, such as Azure Table storage, you’ll be using [OData](http://www.odata.org/)[,](http://www.odata.org/) and all you can do is filter on the primary key and get projections (select a subset of the available fields). |
| Ease of scalability | How often and how much will the data need to scale? Does the platform natively implement scale-out? How easy is it to add or remove capacity (size and throughput)? Relational databases and tables aren’t automatically partitioned to make them scalable, so they are difficult to scale beyond certain limitations. NoSQL data stores such as Azure Table storage inherently partition everything, and there is almost no limit to adding partitions. You can readily scale Table storage up to 200 terabytes, but the maximum database size for Azure SQL Database is 500 gigabytes. You can scale relational data by partitioning it into multiple databases, but setting up an application to support that model involves a lot of programming work. |
| Instrumentation and Manageability | How easy is the platform to instrument, monitor, and manage? You need to remain informed about the health and performance of your data store, so you need to know up front what metrics a platform gives you for free and what you have to develop yourself. |
| Operations | How easy is the platform to deploy and run on Azure? PaaS? IaaS? Linux? Azure Table storage and Azure SQL Database are easy to set up on Azure. Platforms that aren’t built-in Azure PaaS solutions require more effort. |
| API Support | Is an API available that makes it easy to work with the platform? The Azure Table Service has an SDK with a .NET API that supports the .NET 4.5 asynchronous programming model. If you're writing a .NET app, the work to write and test the code will be much easier for the Azure Table Service than for a key/value column data store platform that has no API or a less comprehensive one. |
| Transactional integrity and data consistency | Is it critical that the platform support transactions to guarantee data consistency? For keeping track of bulk emails sent, performance and low data-storage cost might be more important than automatic support for transactions or referential integrity in the data platform, making the Azure Table Service a good choice. For tracking bank account balances or purchase orders, a relational database platform that provides strong transactional guarantees would be a better choice. |
| Business continuity | How easy are backup, restore, and disaster recovery? Sooner or later production data will become corrupted and you’ll need an undo function. Relational databases often have more fine-grained restore capabilities, such as the ability to restore to a point in time. Understanding what restore features are available in each platform you’re considering is an important factor to consider. |
| Cost | If more than one platform can support your data workload, how do they compare in cost? For example, if you use ASP.NET Identity, you can store user profile data in Azure Table Service or Azure SQL Database. If you don't need the rich querying facilities of SQL Database, you might choose Azure Table storage in part because it costs much less for a given amount of storage. |
Microsoft generally recommends that you should know the answer to the questions in each of these categories before you choose your data storage solutions.
In addition, your workload might have specific requirements that some platforms can support better than others. For example:
- Does your application require audit capabilities?
- What are your data longevity requirements—do you require automated archival or purging capabilities?
- Do you have specialized security needs? For example, your data might include personally identifiable information (PII), but you have to be sure that PII is excluded from query results.
- If you have some data that can't be stored in the cloud for regulatory or technological reasons, you might need a cloud data storage platform that facilitates integration with your on-premises storage.
Saturday, May 23, 2015
Pattern : Data Storage




DATA STORAGE OPTIONS ON AZURE
The cloud makes it relatively easy to use a variety of relational and NoSQL data stores. Here are some of the data storage platforms that you can use in Azure.
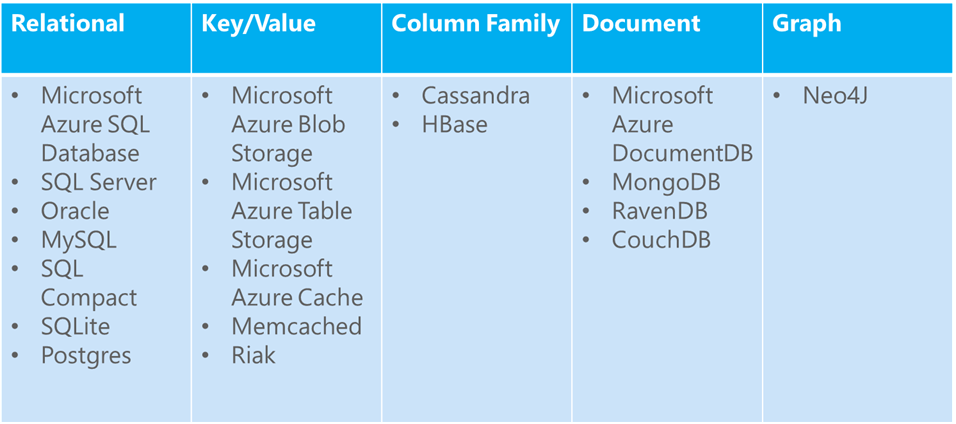
The illustration shows four types of NoSQL databases:
- Key/value databases store a single serialized object for each key value. They’re good for storing large volumes of data in situations where you want to get one item for a given key value and you don’t have to query based on other properties of the item.
- Azure Blob storage is a key/value database that functions like file storage in the cloud, with key values that correspond to folder and file names. You retrieve a file by its folder and file name, not by searching for values in the file contents.
- Azure Table storage is also a key/value database. Each value is called an entity (similar to a row, identified by a partition key and row key) and contains multiple properties (similar to columns, but not all entities in a table have to share the same columns). Querying on columns other than the key is extremely inefficient and should be avoided. For example, you can store user profile data, with one partition storing information about a single user. You could store data such as user name, password hash, birth date, and so forth, in separate properties of one entity or in separate entities in the same partition. But you wouldn't want to query for all users with a given range of birth dates, and you can't execute a join query between your profile table and another table. Table storage is more scalable and less expensive than a relational database, but it doesn't enable complex queries or joins.
- Document databases are key/value databases in which the values are documents. "Document" here isn't used in the sense of a Word or an Excel document but means a collection of named fields and values, any of which could be a child document. For example, in an order history table, an order document might have order number, order date, and customer fields, and the customer field might have name and address fields. The database encodes field data in a format such as XML, YAML, JSON, or BSON, or it can use plain text. One feature that sets document databases apart from other key/value databases is the capability they provide to query on nonkey fields and define secondary indexes, which makes querying more efficient. This capability makes a document database more suitable for applications that need to retrieve data on the basis of criteria more complex than the value of the document key. For example, in a sales order history document database, you could query on various fields, such as product ID, customer ID, customer name, and so forth.
- Azure DocumentDB is a NoSQL document database service designed for modern mobile and web applications. DocumentDB delivers consistently fast reads and writes, schema flexibility, and the ability to easily scale a database up and down on demand. DocumentDB enables complex ad hoc queries using a SQL language, supports well defined consistency levels, and offers JavaScript language integrated, multi-document transaction processing using the familiar programming model of stored procedures, triggers, and UDFs.
- Column-family databases are key/value data stores that enable you to structure data storage into collections of related columns called column families. For example, a census database might have one group of columns for a person's name (first, middle, last), one group for the person's address, and one group for the person's profile information (date of birth, gender, and so on). The database can then store each column family in a separate partition while keeping all of the data for one person related to the same key. You can then read all profile information without having to read through all of the name and address information as well. Cassandra is a popular column-family database.
- Graph databases store information as a collection of objects and relationships. The purpose of a graph database is to enable an application to efficiently perform queries that traverse the network of objects and the relationships between them. For example, the objects might be employees in a human resources database, and you might want to facilitate queries such as "find all employees who directly or indirectly work for Scott." Neo4j is a popular graph database.
Compared with relational databases, the NoSQL options offer far greater scalability and are more cost effective for storage and analysis of unstructured data. The tradeoff is that they don't provide the rich querying and robust data integrity capabilities of relational databases. NoSQL options would work well for IIS log data, which involves high volume with no need for join queries. NoSQL options would not work so well for banking transactions, which require absolute data integrity and involve many relationships to other account-related data.
A newer category of database platforms, called NewSQL, combines the scalability of a NoSQL database with the querying capability and transactional integrity of a relational database.
NewSQL databases are designed for distributed storage and query processing, which are often hard to implement in "OldSQL" databases. NuoDB is an example of a NewSQL database that can be used on Azure.
Sunday, May 17, 2015
Azure AD Integration
What's great for enterprise single sign-on, though, is the Directory Integration tab:
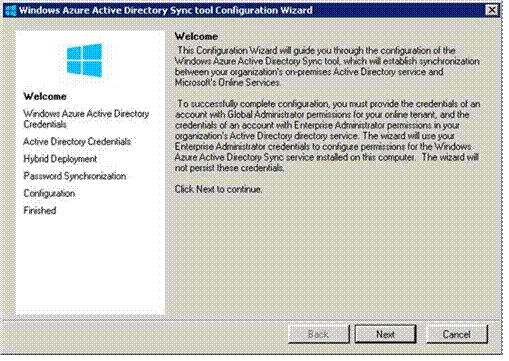
If you enable directory integration and download a tool, you can sync this cloud directory with your existing on-premises Active Directory that you're already using inside your organization. Then, all of the users stored in your directory will show up in this cloud directory. Your cloud apps can now authenticate all of your employees using their existing Active Directory credentials. And all this is free -- both the sync tool and Azure AD itself.
The tool is a wizard that is easy to use, as you can see from the following screen shots. These are not complete instructions, just an example showing you the basic process. For more detailed how-to-do-it information, see the links in the Resources section at the end of the chapter.
First you see the Welcome page.
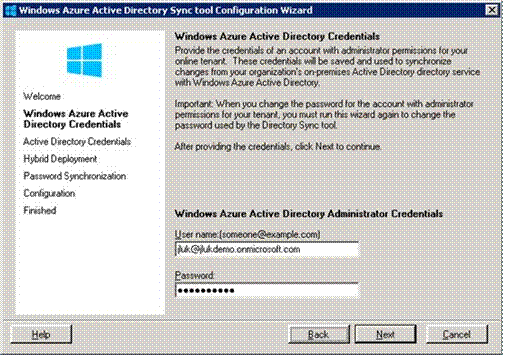
Click Next, and then enter your Azure Active Directory credentials.
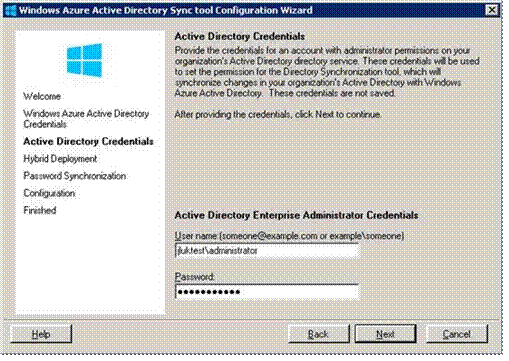
Click Next, and then enter your on-premises AD credentials.
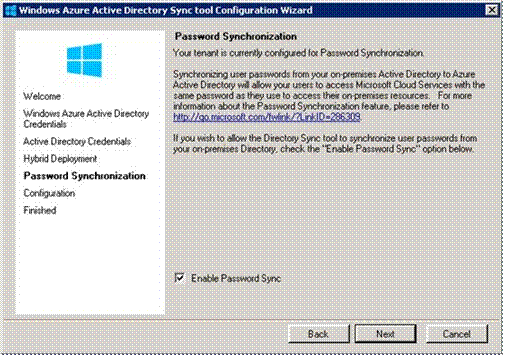
Click Next, and then indicate whether you want to store a hash of your AD passwords in the cloud.
The password hash that you can store in the cloud is a one-way hash; actual passwords are never stored in Azure AD. If you decide against storing hashes in the cloud, you'll have to use Active Directory Federation Services (ADFS). There are also other factors to consider when choosing whether to use ADFS. The ADFS option requires a few additional configuration steps.
If you choose to store hashes in the cloud, you're done, and the tool starts synchronizing directories when you click Next.
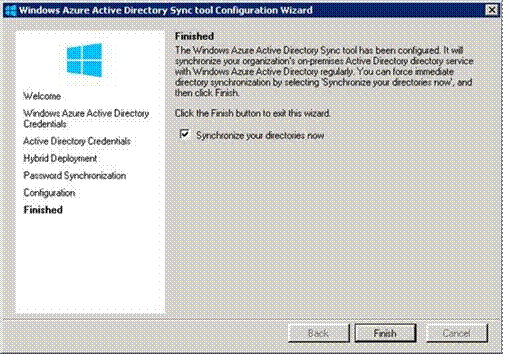
And in a few minutes you're done.
You only have to run this wizard on one domain controller in the organization; the server must be running Windows Server 2003 or higher. And no need to reboot. When you're done, all of your users are set up in the cloud, and you can do single sign-on from any web or mobile application, using SAML, OAuth, or WS-Fed.
Thursday, May 14, 2015
Availability Sets
There are two kinds of maintenance events:
1. Planned maintenance events
2. Un-planned maintenance events
There are instances that require a VM reboot.
You can add one or more VM to the availability set.
Each VM in Availability Sets are assigned the following
a. Fault Domain
b. Update Domain
1. Planned maintenance events
2. Un-planned maintenance events
There are instances that require a VM reboot.
You can add one or more VM to the availability set.
Each VM in Availability Sets are assigned the following
a. Fault Domain
b. Update Domain
Virtual Network (vNet)
1. Creates a Virtual Network so Virtual Machines can communicate safely
2. Provides a layer of security by providing a layer of isolation
3. Can connect on premise computers to the Virtual Network in Azure via an Azure Virtual Network Gateway.
2. Provides a layer of security by providing a layer of isolation
3. Can connect on premise computers to the Virtual Network in Azure via an Azure Virtual Network Gateway.
- Site-to-Site - connecting on premise networks with Virtual Networks
- “Hybrid Cloud”
- Point-to-Site - connecting a single computer to a Virtual Network
4. When to use Virtual Network?
- Create a dedicated private cloud-only network for VMs already in Azure
- Securely extend your data center to the cloud
- Enable hybrid cloud scenarios to connect cloud-based applications to on premise services (db, web services, etc.)
Relationship between VM and Cloud Services
1. Hosted service or Cloud Service
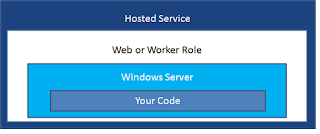
2. A real windows virtual machine was hosted inside of a role in cloud service
3. You can add multiple VMs into a single Cloud Service
- Provided an IP address that was connected to load balancer

2. A real windows virtual machine was hosted inside of a role in cloud service
3. You can add multiple VMs into a single Cloud Service
- Best practice: put VMs from the same logical application tier into the same cloud service (i.e., presentation tier, middle tier, persistence tier)
- Virtual Networks are recommended way to allow to talk to each other
4. VMs must live in a cloud service, a container providing a unique public DNS name, a public and private IP, and endpoints
Virtual Machine Storage
VM Storage
There are two disks:
a. Operating System Disk - Hosts OS
b. Temporary Disk - Temporary Storage like page file caching, unreliable for long term storage (d:\)
When you provision a new VM, a copy of Virtual Hard Drive image is added to your Azure Blob Storage account. Hard Drive Image is mounted to your Virtual Machine Instance.
There are two types of persistent disks, both comprised of Page Blobs (Get high availability, durability, geo-redundancy)
1. OS Disk (c:\)
2. Data Disk - Preferred Disk for Long Term Data (e:\)
There are two disks:
a. Operating System Disk - Hosts OS
b. Temporary Disk - Temporary Storage like page file caching, unreliable for long term storage (d:\)
When you provision a new VM, a copy of Virtual Hard Drive image is added to your Azure Blob Storage account. Hard Drive Image is mounted to your Virtual Machine Instance.
There are two types of persistent disks, both comprised of Page Blobs (Get high availability, durability, geo-redundancy)
1. OS Disk (c:\)
2. Data Disk - Preferred Disk for Long Term Data (e:\)
Azure Loadbalancer
Spreads incoming requests to multiple servers to handle load so that incoming requests don't pile up and response time don't increase.
Azure uses simple random distribution of traffic.
Azure load balancer distributes loads to VMs inside of the same "load balanced set".
Availability sets - protect against downtime
Loadbalanced set - improves response time
In practice, they are same.
There are three types of load balancing in azure:
1. Traffic Manager - DNS Level, distributing to different data centers based on geo-location
2. Azure Load Balancer - Network level, distributes traffic from outside of Azure to VMs/Service inside of Azure
3. Internal Load Balancer - Network level, distributes traffic from inside of Azure to VMs/Service inside of Azure



http://bit.do/configure-load-balanced-set
http://bit.do/configure-internal-load-balanced-set
Azure uses simple random distribution of traffic.
Azure load balancer distributes loads to VMs inside of the same "load balanced set".
Availability sets - protect against downtime
Loadbalanced set - improves response time
In practice, they are same.
There are three types of load balancing in azure:
1. Traffic Manager - DNS Level, distributing to different data centers based on geo-location
2. Azure Load Balancer - Network level, distributes traffic from outside of Azure to VMs/Service inside of Azure
3. Internal Load Balancer - Network level, distributes traffic from inside of Azure to VMs/Service inside of Azure



http://bit.do/configure-load-balanced-set
http://bit.do/configure-internal-load-balanced-set
Pattern : Single Sign On
INTRODUCTION TO AZURE ACTIVE DIRECTORY
- It integrates with on-premises Active Directory.
- It enables single sign-on with your apps.
- It supports open standards such as SAML, WS-Fed, and OAuth 2.0.
- It supports Azure AD Graph REST API.
Suppose you have an on-premises Windows Server Active Directory environment that you use to enable employees to sign on to intranet apps:
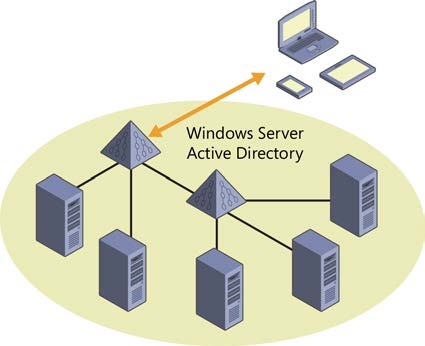
What Azure AD enables you to do is create a directory in the cloud. It’s a free feature and easy to set up.
This directory can be entirely independent from your on-premises Active Directory; you can put any user you want in it and authenticate them in Internet apps.
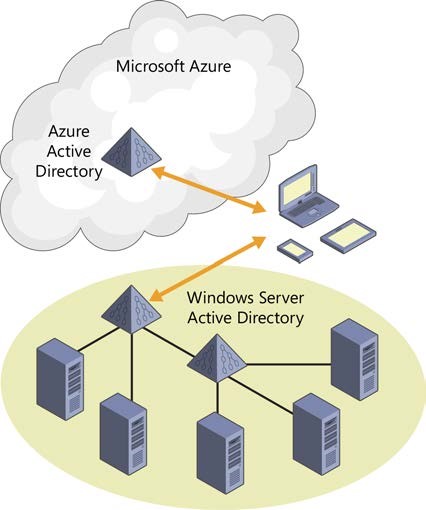
Or you can integrate it with your on-premises AD.
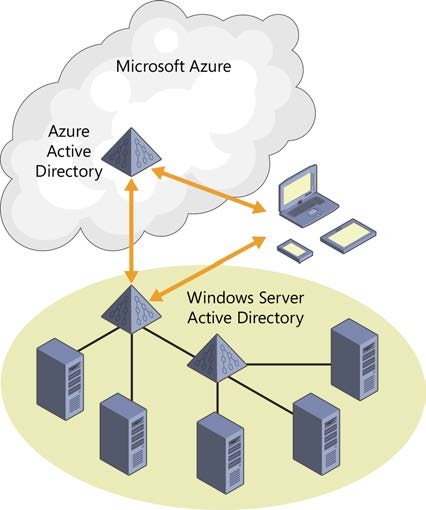
Now all the employees who can authenticate on-premises can also authenticate over the Internet— without you having to open up a firewall or deploy any new servers in your data center. You can continue to leverage all the capabilities of the existing Active Directory environment that you know and use today to give your internal apps single-sign on capability.
Once you’ve made this connection between AD and Azure AD, you can also enable your web apps and your mobile devices to authenticate your employees in the cloud, and you can enable third-party apps, such as Office 365, SalesForce.com, or Google apps, to accept your employees’ credentials. If you're using Office 365, you're already set up with Azure AD because Office 365 uses it for authentication and authorization.

The beauty of this approach is that any time your organization adds or deletes a user, or a user changes a password, you use the same process that you use today in your on-premises environment. All of your on-premises AD changes are automatically propagated to the cloud environment.
If your company is using or moving to Office 365, the good news is that Azure AD will be set up automatically. So you can easily use the same authentication that Office 365 uses in your own apps.
Connecting to a VM
Connecting to VM
1. By default, only RDP and Remote Powershell is enabled.
2. To connect to anything else, you must enable EndPoints. When you are creating an endpoint, you are actually creating a mapping in Azure Loadbalancer to your VM on a port.
3. Your virtual machine is provisioned with a virtual ip address for external communication (via the internet) and another ip address for internal communication (via the load balancer)
a. A public-facing Virtual IP
- Internet Visible so that you can point a DNS record to
- Available to you as long as you do not shut down the machine
- Reserved IP Address
- Permanently associated with your subscription
- 5 reserved IP addresses per subscription
- Only way to do through is powesrshell
- Used by load balancer to route requests in load balancing scenario
- Used by VMs in a Virtual Network to communicate with each other
- Static IP Address
- Private IPs that are permanently associated with your subscription
- Only available for VMs inside of Virtual Networks
c. Problem: Not sticky to your subscription

Virtual Machines - Factors Affecting Costs
Costs
There are four basic components that affect costs:
1. Windows vs. Linux
2. Computational Power Required
3. Service Tiers (Basic vs. Standard) e.g. Load Balancing
4. Data Center Region
5. Additional Software License (pre-configured software)
http://bit.do/vm-pricing
Billed per minute, You are paying until you shutdown
Virtual Machine Series
1. A-Series : General Purpose, used for development and testing. Not suitable for production.
2. D-Series : 60% Faster CPUs, SSD Drives
3. G-Series : Fastest, Most modern hardware, Massive amounts of CPU, RAM and Storage available
There are four basic components that affect costs:
1. Windows vs. Linux
2. Computational Power Required
3. Service Tiers (Basic vs. Standard) e.g. Load Balancing
4. Data Center Region
5. Additional Software License (pre-configured software)
http://bit.do/vm-pricing
Billed per minute, You are paying until you shutdown
Virtual Machine Series
1. A-Series : General Purpose, used for development and testing. Not suitable for production.
2. D-Series : 60% Faster CPUs, SSD Drives
3. G-Series : Fastest, Most modern hardware, Massive amounts of CPU, RAM and Storage available
Subscribe to:
Posts (Atom)