



DATA STORAGE OPTIONS ON AZURE
The cloud makes it relatively easy to use a variety of relational and NoSQL data stores. Here are some of the data storage platforms that you can use in Azure.
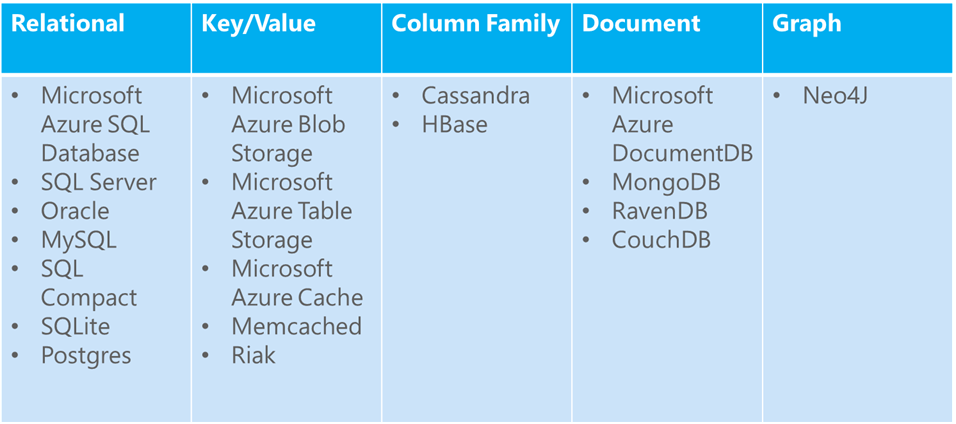
The illustration shows four types of NoSQL databases:
- Key/value databases store a single serialized object for each key value. They’re good for storing large volumes of data in situations where you want to get one item for a given key value and you don’t have to query based on other properties of the item.
- Azure Blob storage is a key/value database that functions like file storage in the cloud, with key values that correspond to folder and file names. You retrieve a file by its folder and file name, not by searching for values in the file contents.
- Azure Table storage is also a key/value database. Each value is called an entity (similar to a row, identified by a partition key and row key) and contains multiple properties (similar to columns, but not all entities in a table have to share the same columns). Querying on columns other than the key is extremely inefficient and should be avoided. For example, you can store user profile data, with one partition storing information about a single user. You could store data such as user name, password hash, birth date, and so forth, in separate properties of one entity or in separate entities in the same partition. But you wouldn't want to query for all users with a given range of birth dates, and you can't execute a join query between your profile table and another table. Table storage is more scalable and less expensive than a relational database, but it doesn't enable complex queries or joins.
- Document databases are key/value databases in which the values are documents. "Document" here isn't used in the sense of a Word or an Excel document but means a collection of named fields and values, any of which could be a child document. For example, in an order history table, an order document might have order number, order date, and customer fields, and the customer field might have name and address fields. The database encodes field data in a format such as XML, YAML, JSON, or BSON, or it can use plain text. One feature that sets document databases apart from other key/value databases is the capability they provide to query on nonkey fields and define secondary indexes, which makes querying more efficient. This capability makes a document database more suitable for applications that need to retrieve data on the basis of criteria more complex than the value of the document key. For example, in a sales order history document database, you could query on various fields, such as product ID, customer ID, customer name, and so forth.
- Azure DocumentDB is a NoSQL document database service designed for modern mobile and web applications. DocumentDB delivers consistently fast reads and writes, schema flexibility, and the ability to easily scale a database up and down on demand. DocumentDB enables complex ad hoc queries using a SQL language, supports well defined consistency levels, and offers JavaScript language integrated, multi-document transaction processing using the familiar programming model of stored procedures, triggers, and UDFs.
- Column-family databases are key/value data stores that enable you to structure data storage into collections of related columns called column families. For example, a census database might have one group of columns for a person's name (first, middle, last), one group for the person's address, and one group for the person's profile information (date of birth, gender, and so on). The database can then store each column family in a separate partition while keeping all of the data for one person related to the same key. You can then read all profile information without having to read through all of the name and address information as well. Cassandra is a popular column-family database.
- Graph databases store information as a collection of objects and relationships. The purpose of a graph database is to enable an application to efficiently perform queries that traverse the network of objects and the relationships between them. For example, the objects might be employees in a human resources database, and you might want to facilitate queries such as "find all employees who directly or indirectly work for Scott." Neo4j is a popular graph database.
Compared with relational databases, the NoSQL options offer far greater scalability and are more cost effective for storage and analysis of unstructured data. The tradeoff is that they don't provide the rich querying and robust data integrity capabilities of relational databases. NoSQL options would work well for IIS log data, which involves high volume with no need for join queries. NoSQL options would not work so well for banking transactions, which require absolute data integrity and involve many relationships to other account-related data.
A newer category of database platforms, called NewSQL, combines the scalability of a NoSQL database with the querying capability and transactional integrity of a relational database.
NewSQL databases are designed for distributed storage and query processing, which are often hard to implement in "OldSQL" databases. NuoDB is an example of a NewSQL database that can be used on Azure.
very informative blog and useful article thank you for sharing with us , keep posting learn more
ReplyDeleteAzure Online Course Hyderabad
ReplyDeleteNice Information. Thanks for sharing this Post.
Microsoft Windows Azure Training | Online Course | Certification in chennai | Microsoft Windows Azure Training | Online Course | Certification in bangalore | Microsoft Windows Azure Training | Online Course | Certification in hyderabad | Microsoft Windows Azure Training | Online Course | Certification in pune
perde modelleri
ReplyDeletesms onay
Vodafone Mobil Ödeme Bozdurma
nft nasil alınır
Ankara Evden Eve Nakliyat
TRAFİK SİGORTASİ
Dedektor
web sitesi kurma
Aşk Romanları